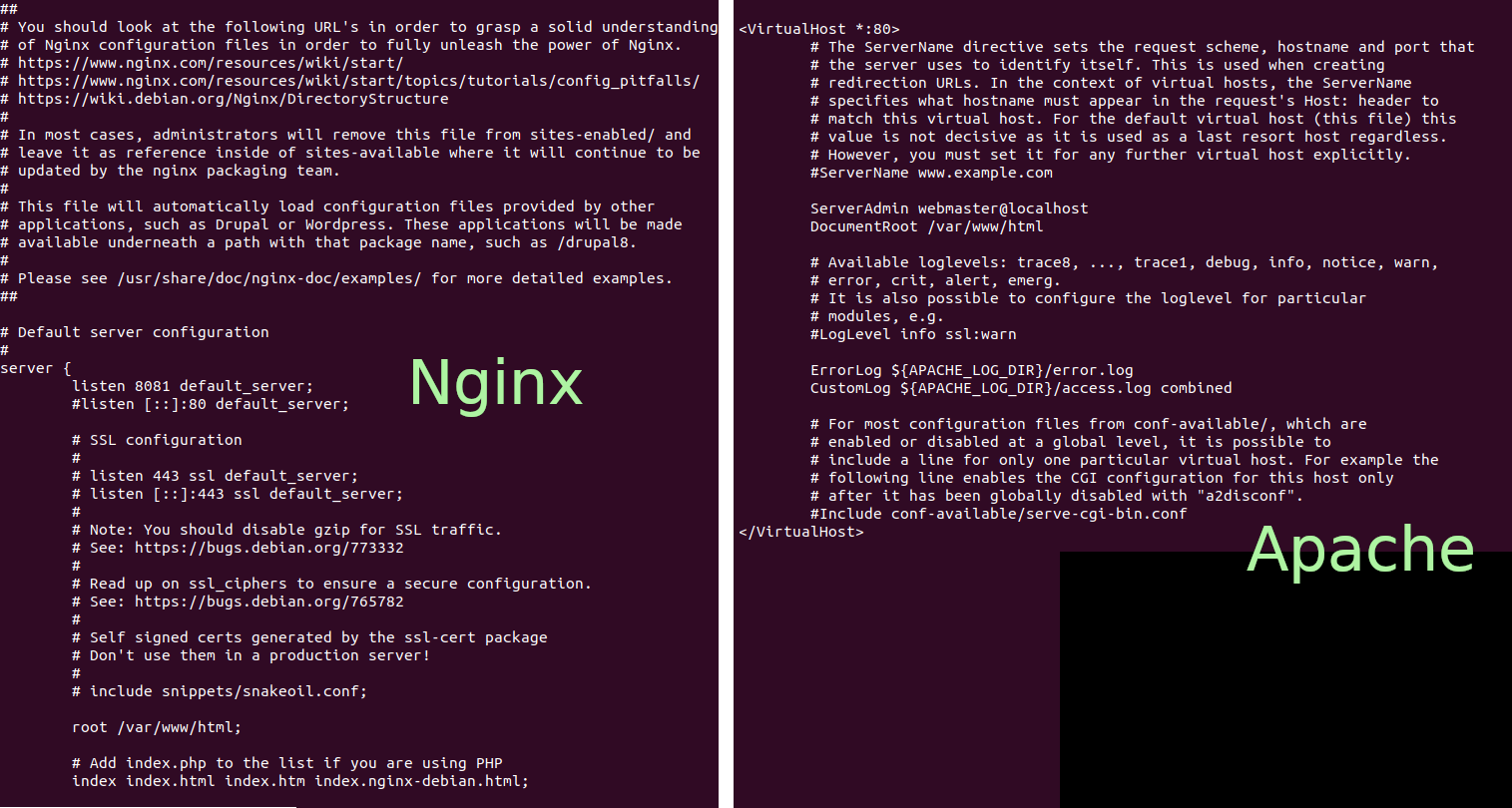
Config files are trees
In our last post we looked at problems with the inconsistency of configuration file formats, but what's the answer? Most config files have some sort of tree structure – consider a webserver as an example, these have a set of server names and then within each server there’s a set of configuration entries for locations etc. Would some sort of tree of trees be suitable?
With a tree structure, upgrades could easily insert a new node, or have a well-defined ‘tree diff’ of nodes to insert, change or remove, rather than the less robust method of trying to programmatically slice up and insert text into a config file.
You could also have a grammar that defined permitted entries in the tree, and that definition could be used for validation. Add to this per-node/branch permissions and you have a fine grained permissions structure. Documentation could be included in the tree definition which could be extracted to build documentation, rather like Javadoc does for any Java program or Sphinx/Autodoc does for Python. ‘Types’ could be defined for nodes, e.g. enumerated lists that defined all possible options that could be used by configuration checkers, documentation or GUI tools.
Add idempotent APIs to manipulate the trees and with IaaS, configurations could be stored and applied – e.g. at setup, or any point in the life of a server, a tree representing the config to deploy could be used, rather than effectively trying to mechanically edit config files through pattern matching and anchor points, that can’t cope if a config file has deviated from what’s expected.
This approach is not too dissimilar from Microsoft's Windows Registry that provides a tree of config values and files that can act as ‘tree diffs’ that specify nodes to add etc.
Moving on
There are reasons why it became standard to use some sort of text file to hold configuration data. Many were created in an earlier era of computing; before the likes of YAML, JSON and XML had been invented. Also, in some ways we’re just as guilty – when we needed a config for CodeBug Connect for WiFi; we wanted something simple for users, so we went for a text file. In our defence we do provide an API to update that text file and for other configs we used JSON.
But if the configuration of everything in Linux were to be a tree, it would be easy to create web APIs that could manipulate them. There’s a clear need for this when you look at VyOS, pfsense (I know strictly it’s not Linux but BSD based) or similar, which all have complicated logic to generate config files to drive applications and systems such as firewalls, vpns etc. The GUIs are almost completely disconnected too – when a new configuration option is made available to a config file, completely separate logic needs to be implemented to make that option appear in a menu etc..
There’s hope on the way though in that newer features of Linux handle configuration more sensibly. For example, Netplan, which sets up the network, uses a YAML format, and then has ‘renderers’ that apply it. There are also mechanisms, such as cloud-init to allow these configuration files to be applied to new servers as they’re being commissioned.
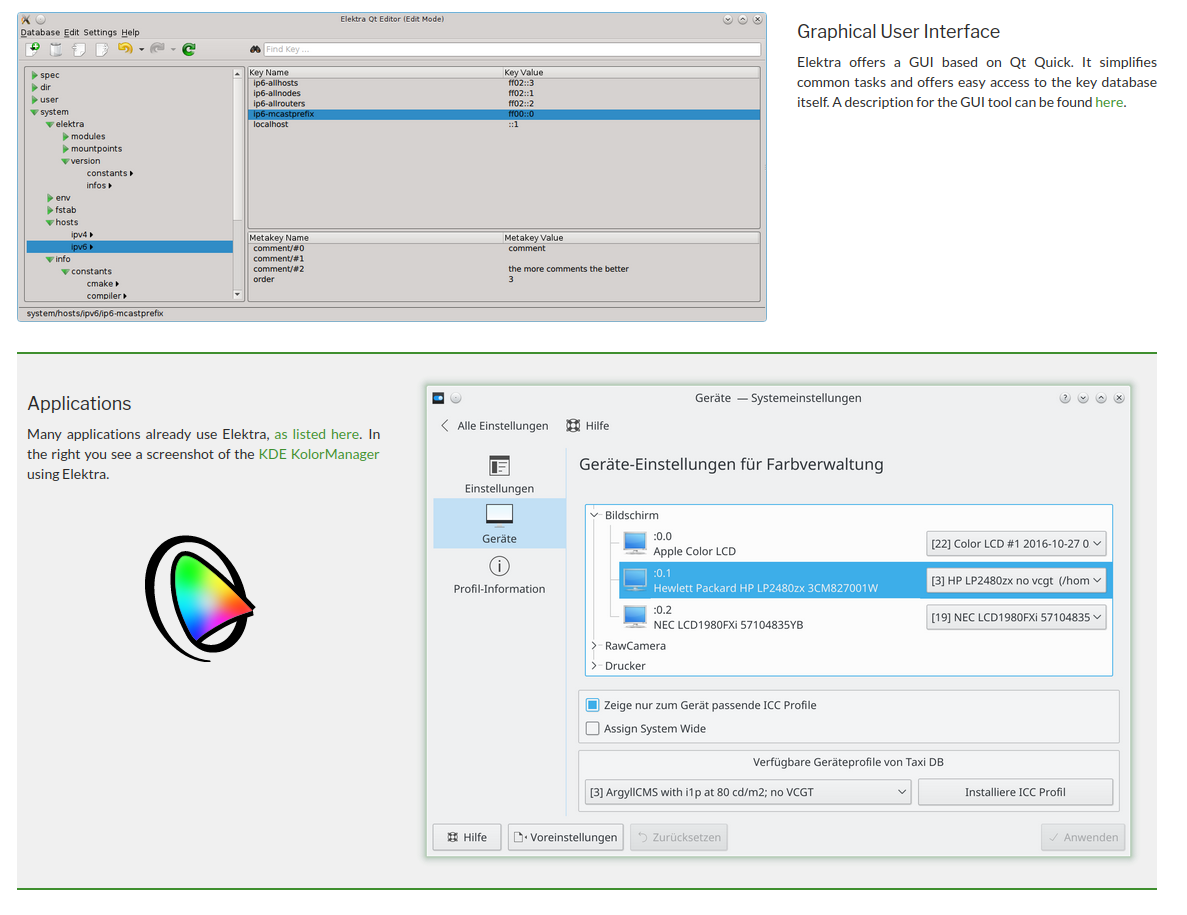
The Elektra Project is making early steps and we'll be watching closely to see if more applications adopt it.
There are still opportunities to make this work in a standard reusable way and to create standard tools that can find and merge differences in configs, or for graphical editors to provide more flexibility to users.
Wouldn’t it be easier if Linux, its applications and its utils all offered a well thought out API, achieved through a reusable set of libraries and tooling rather than a jumble of text files?